Building the Custom Chat Engine: Implementation Deep Dive
The provider layer, agentic loop, and streaming protocol. Part 1 covered why we moved away from the Vercel AI SDK.
Part 1 explained why we replaced the server side of the Vercel AI SDK. This post covers how we built the replacement — the provider abstraction, the agentic loop, and the streaming protocol that ties it all together.
The Provider Abstraction
The SDK's provider abstraction was too thin (just swap a model name) and too thick (it hides everything useful). We needed something in between.
We defined an interface that every provider must implement:
Each provider implements this interface using its native SDK — not the Vercel wrapper. The Anthropic provider uses @anthropic-ai/sdk directly. The Gemini provider uses @google/genai directly. This gives us access to every provider-specific feature: prompt caching, extended thinking, beta headers, detailed token usage.
A factory creates the right provider based on configuration, and a load balancer distributes requests across multiple API keys for rate limit management.
The Agentic Loop
This is the heart of the system — the part that makes it an agent rather than a chatbot.
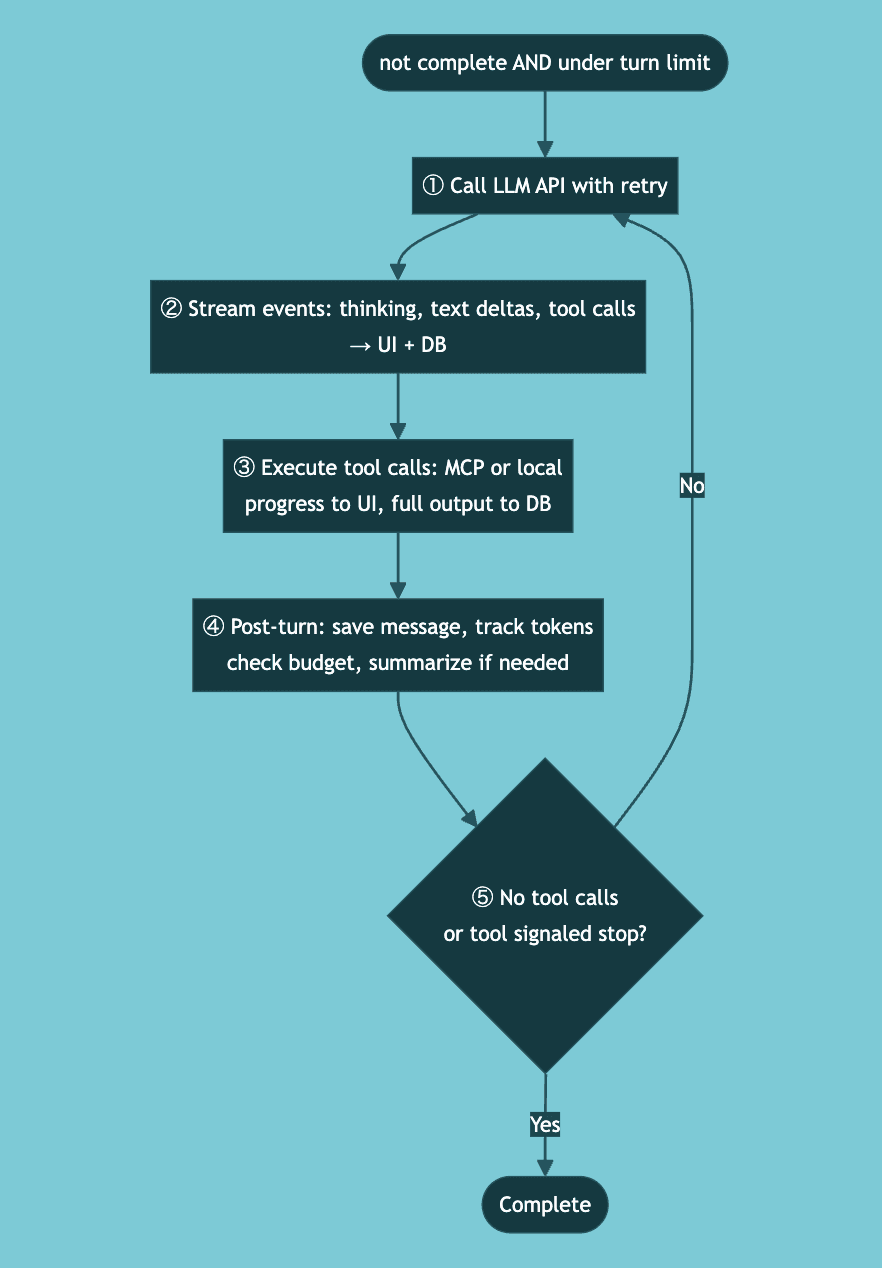
Each turn is a complete LLM API call. The provider streams raw events (text deltas, tool calls, thinking blocks), and we process each one as it arrives — streaming to the UI and persisting to the database simultaneously. If the server crashes at any point, the database has everything up to the last successfully processed event.
Dynamic Tool Discovery
One pattern worth highlighting: runtime tool loading. The loop starts with preloaded tools based on the user's connected integrations. But mid-conversation, the LLM might need tools that weren't preloaded.
When the LLM calls our find_tools meta-tool, the response includes new tool definitions that get injected into the mutable registry. On the very next turn, those tools are available — no restart needed. From the LLM's perspective, the tools were always there.
The Stream Protocol
We kept useChat on the frontend, which means our server must emit events in a format the hook understands. The Vercel AI SDK uses a line-based protocol where each event has a type prefix.
We encode this ourselves:
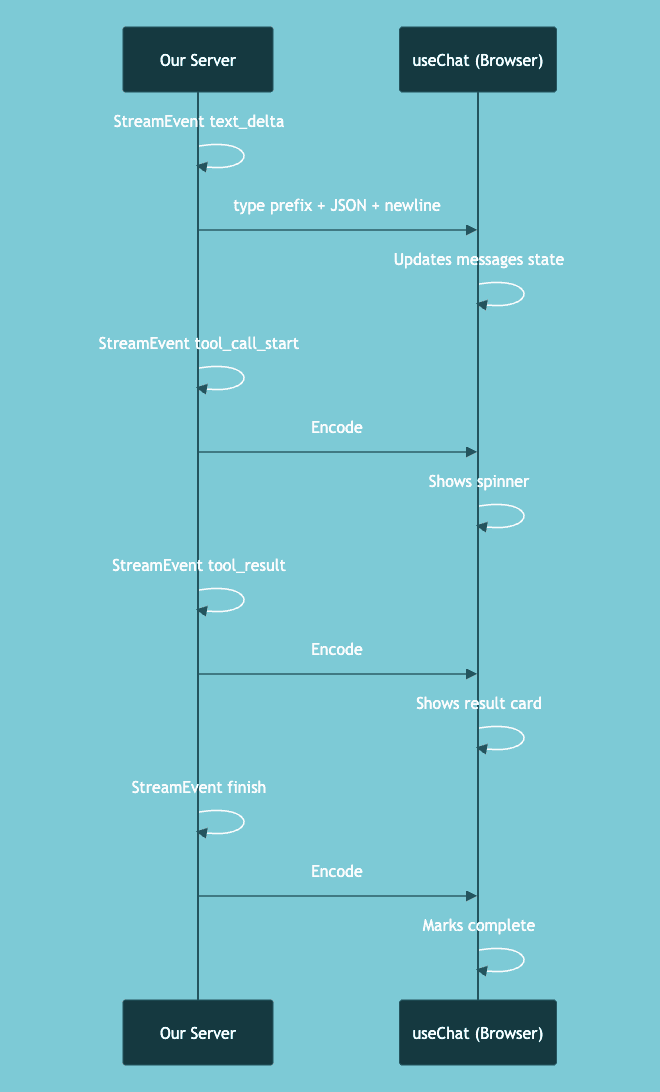
The event types we support go beyond what the SDK natively offers: text_delta, thinking, tool_call_start, tool_call_delta, tool_call_done, tool_result, step_start, data, finish, error.
This is a calculated risk. We depend on the wire protocol being stable. If Vercel changes the format, our encoding breaks. We've accepted that tradeoff because rewriting the frontend state management would be significantly more work, and the protocol has been stable so far.
Message Format Translation
Each LLM provider has its own message format. Anthropic uses a content-block model with typed arrays. Gemini uses a parts-based model with function calls. The conversation needs to flow through both without losing information.
We store messages in our own internal format in the database. Each provider's translation layer converts to/from the provider-native format. The rest of the system — database storage, token estimation, summarization — all operate on one consistent shape. Provider-specific formats are a concern of the provider layer alone.
Error Handling
Not all failures are equal. We built an error classification system to decide whether to retry:
Transient (retry makes sense):
Server overloaded
Rate limited
Network error
→ Exponential backoff, try fallback provider if available
Permanent (retry won't help):
Invalid request
Auth failure
Context too long
Quota exceeded
→ Show clear error to user with appropriate action (upgrade, new chat, retry)
Each error type maps to a specific user experience. Rate limits get a retry button. Context length errors suggest starting a new chat. Quota exceeded shows an upgrade path. This is only possible because we handle errors at the individual turn level.
End-to-End Example
User types: "Analyze my top Google Ads campaigns and generate a report."
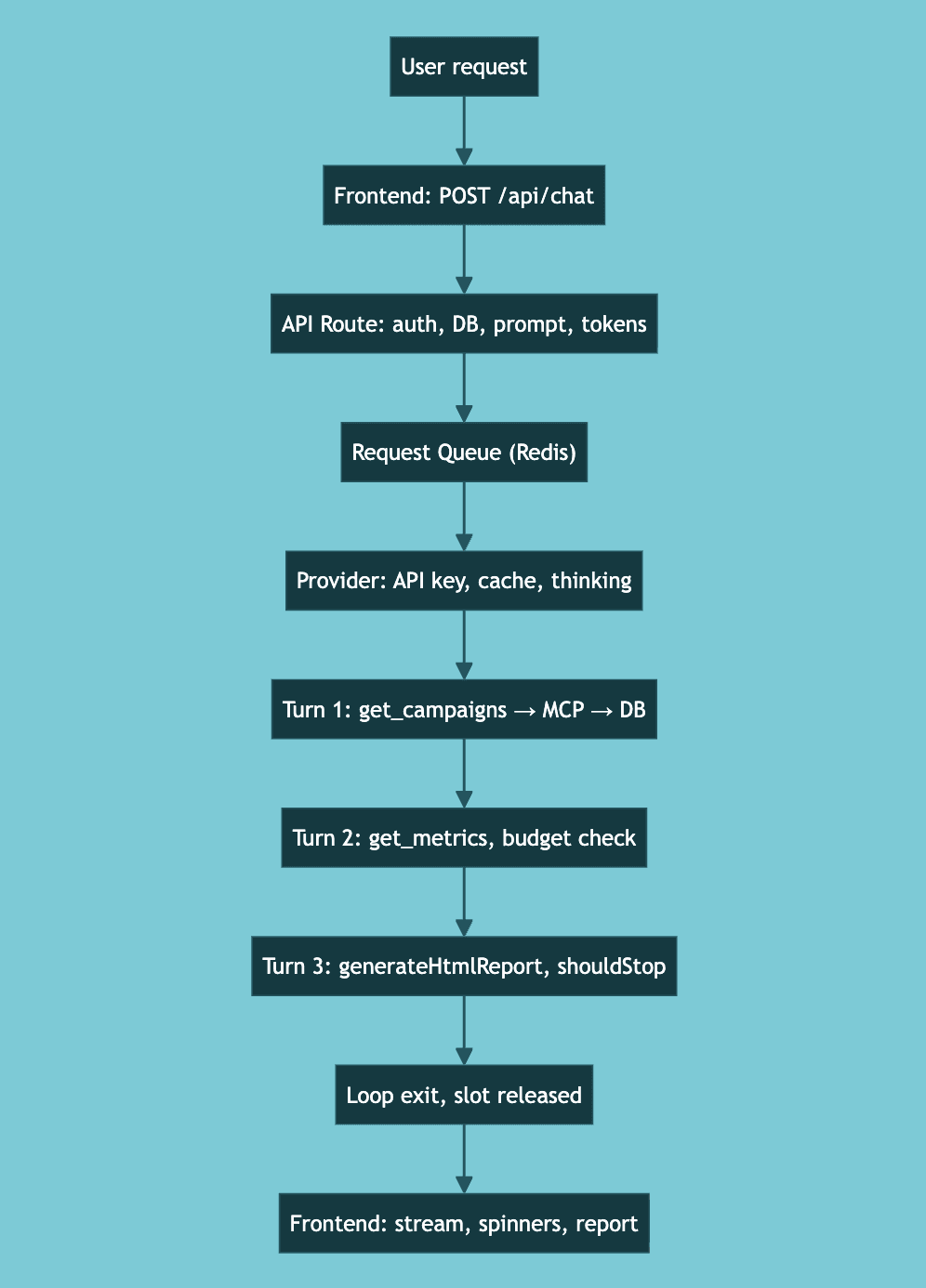
Frontend prepares request with metadata, sends POST to
/api/chatAPI Route validates auth, creates chat in DB, saves user message, builds system prompt, loads history, estimates tokens, triggers summarization if needed
Request Queue (Redis - backed) checks capacity, queues if full, acquires processing slot
Provider creates client with rotated API key, sends request with cache control, enables extended thinking
Agentic Loop — Turn 1: LLM streams "I'll analyze your campaigns", calls
google_ads_get_campaigns, executes via MCP, saves full output to DB, feeds truncated version backAgentic Loop — Turn 2: LLM analyzes data, calls
google_ads_get_campaign_metrics, token budget checkedAgentic Loop — Turn 3: LLM calls
generateHtmlReport, tool signalsshouldStop = trueLoop exits: Final metadata saved, finish event emitted, processing slot released
Frontend renders: Text appears word by word, tool calls show spinners then checkmarks, report renders inline
Three LLM turns, three tool executions, one report — all streamed in real-time, with every piece persisted along the way.
Looking Back
The custom engine is roughly 3,000 lines of code. That's code we maintain, test, and debug ourselves. When a new Anthropic or Gemini API version drops, we update our provider — not waiting for the SDK to catch up.
The architecture has held up well. Adding new providers is straightforward — implement the interface, handle the format translation, and it slots in. Adding new event types to the stream just requires updating the encoder. The agentic loop's structure has remained stable even as we've added features.
Previously
Part 1: Why We Ripped Out the Vercel AI SDK and Built Our Own